


o3, o4-mini: Largely Incremental at Math
Reviewing the math capabilities of the new models

OpenAI released o3 and o4-mini last week. I’ll use this post to review the new models against standard math benchmarks, as well as on some of the less-formal evaluations I’ve developed in previous posts. I’ll also discuss my sense of the current trajectory of math capabilities, since we might be near the end of a frontier model release cycle.
TL;DR: in terms of math, the new models are an incremental step forward compared to OpenAI’s previous models. Their progress comes from tightening up existing capabilities rather than breaking new ground. They are roughly tied with Gemini 2.5 Pro as “best math model”. From the anecdotal excitement I’ve seen about these new models, it seems like OpenAI achieved more progress in other, non-math areas. I wouldn’t be surprised if that trend continues.
Benchmark Roundup
It’s becoming pleasantly routine to scan through third-party benchmarks. Thanks to everyone who creates and maintains there!
Short-Answer Competitions
First, the three short-answer competitions evaluated on MathArena:
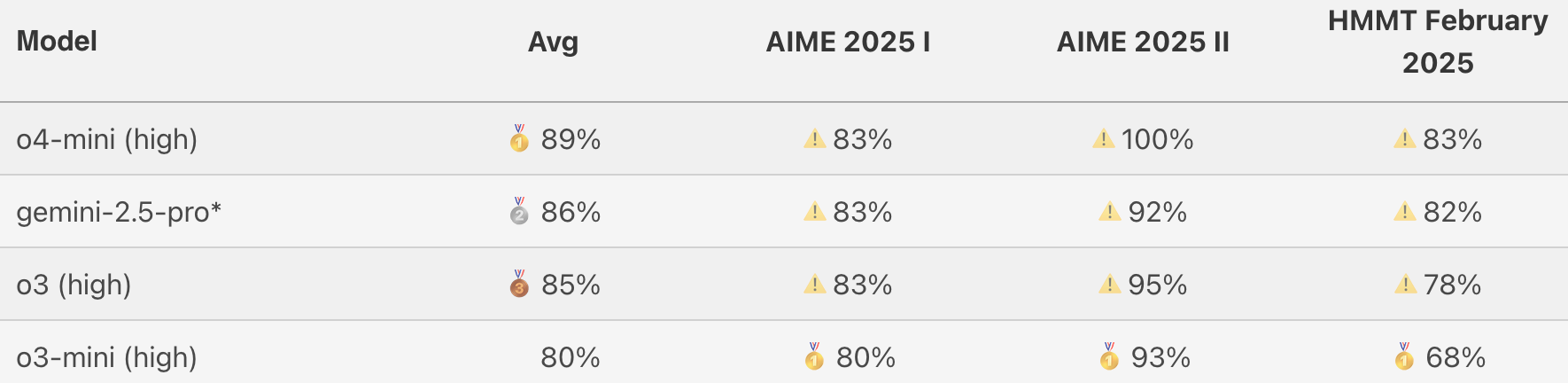
The headline differences are due to the 2025 AIME II, where o4-mini-high in particular got a perfect score. Note, however, that this test is the easiest of the bunch, and that prior models already got all of the questions right at least half the time.

Thus, I think this fits with the claim that the models tighten up existing performance rather than break new ground. To be fair, though, there isn’t much room left to break new ground on these tests.
Proof-Based Competitions
Next up: the 2025 USAMO. This is a proof-based competition for which MathArena provides systematic human grading of AI solutions.

Previously o3-mini-high (not pictured) got <5%. The new models have joined Gemini 2.5 Pro in getting ≈20%. This looks a bit like breaking new ground, but, as I wrote in a previous post, I think it is actually an artifact of the coarse-grained metric. o3-mini-high had much of the “raw material” needed for getting the first problem, but just wasn’t putting it all together. It seemed reasonable to expect that the next iteration would improve. Here we are: o3 and o4-mini-high do fine on the first problem. Also, like Gemini 2.5 Pro, they are sometimes able to coordinate bash their way to a solution to the fourth problem. See the linked posts for more discussion, but overall this too looks like tightening up performance rather than breaking new ground.
FrontierMath
I’ve written about FrontierMath before, but technical difficulties have prevented Epoch from evaluating Gemini 2.5 Pro on the benchmark so there hasn’t been much to report. Now, though, we have numbers for the new OpenAI models:

o1, o3-mini-high, and o3 are all level with each other around 10%. o4-mini-high scored higher, at 17%. I think it’s fair to characterize that as incremental progress, and, given that it’s a private dataset, there might not be much more to say.1
Benchmark Conclusions
The systematic benchmarks certainly seem to point to incremental progress over any sort of phase change in abilities. Also, on net, it looks like o4-mini-high is a bit better than o3 on these benchmarks. That’s nice, at least, given the cost difference!
Informal Evaluations
I’ll now go through the less-formal evaluations I’ve explored in previous posts.2
Memory
o4-mini-high doesn’t seem much better than o3-mini-high at remembering specific historical problems. For instance, it still can’t recall P6 from the 1988 IMO, one of the most famous and widely-discussed IMO problems. Moreover, if given the problem, it recognizes the general technique needed to solve it, but bluffs over the critical details. Note that Gemini 2.5 Pro recalls both the problem and the solution.
I repeated the same experiment I described in the post on data contamination. The idea was, if you filter to hard IMO problems with short-form answers, and control for how “guessable” the answers are, you can see whether the model has memorized the answers. o3-mini-high got only 2/9 of the problems I assessed to be not too guessable, suggesting its memory for the answers wasn’t very strong. o4-mini-high, on the other hand, got 6/9 of them.

I do think that’s probably mostly because it has gotten better at guessing: its summarized chains of thought on these problems certainly suggest it’s just working through small examples and extrapolating a pattern—just doing so with more diligence than I initially gave it credit for.
Still, it’s hard to rule out that it may be guided in this search by data it saw in pre-training. So, while I think o4-mini-high is still unlikely to be memorizing solutions to problems, this conclusion is probably uncertain enough that it’s worth doing a more refined experiment before using any pre-training-cutoff data in any significant analysis.
Proof Rating
I repeated the experiment developed in the previous post, using a series of two prompts to have the model self-assess its solutions to the 12 problems from the 2024 IMO and 2025 USAMO.
Here are o4-mini-high’s results after the first round, where it is supposed to self-report if it failed to find a complete proof:
1 True Positive3: didn’t report failure, and was right not to
7 False Positives: didn’t report failure, but should have
4 True Negatives: reported failure, and was right to
0 False Negatives: reported failure, but should not have
And here are the cumulative results after the second round, where, in a fresh session, it is supposed to rate the proof it gave previously, judging whether the proof has significant gaps or is largely complete.
1 True Positive
3 False Positives
8 True Negatives
0 False Negatives
Both filters have some signal and the final tally is better than it was for o3-mini-high, which didn’t seem inclined to critique its own proofs. Of course, it’s a small dataset.
For what it’s worth, as with Gemini 2.5 Pro, the final false positives include my favorite recent problem: Turbo the snail from the 2024 IMO.
Overall, my impression is that o4-mini-high has a better grasp of what makes for a valid proof than o3-mini-high did, but is still probably a bit behind Gemini 2.5 Pro on this front. I should be clear: I’m basing that as much on what I’ve seen of the models’ proof-writing styles as on any of the data above.
An Emerging Picture
One result I didn’t expect: o4-mini-high gets the combinatorics problem from HMMT that I’ve discussed previously. This isn’t such a hard problem for humans, but the human way to solve it is basically just drawing a diagram and staring at it until it becomes clear what’s going on. There isn’t much of an alternative: you can try to execute a dynamic program by hand, but that is a bit too arduous for the models. o4-mini-high is the first to solve it the “right way”, effectively working through the diagrammatic reasoning.

This doesn’t represent a big breakthrough so much as filling in a gap that seemed out of place, and harder diagrammatic combinatorics questions remain out of reach, e.g. HMMT C9. It’s nonetheless an interesting little proof by possibility: new forms of reasoning can indeed emerge as the models scale up.
Informal Conclusions
The practical takeaway is probably just that, if you have a math task that you suspect doesn’t require too much out-of-the-box thinking or too strong a grasp on proofs, then it’s worth seeing what o4-mini-high and/or Gemini 2.5 Pro make of it.
One thing I haven’t evaluated is how these models do when tool use is relevant. o3/o4-mini are supposed to be very good at repeatedly writing code and doing searches while working on a larger task. The evaluations I’ve discussed so far are just about “inherent” math capabilities, but surely these tool-based workflows are useful for some math tasks.
Indeed, just before posting, I saw mathematician Daniel Litt commenting to this effect:

That’s as good a summary as I could hope to give about the value they offer to working mathematicians. If you’re not doing research math, you might even get your hopes up a bit higher—so long as you’re willing and able to check their work.
Where Are We Going?
I was struck by this chart from a researcher at OpenAI.

Because, isn’t that logarithmic? Or, more qualitatively, it seems clear that o1 was a big step up over the GPTs. There was clearly an innovation around combining RL for math problems with a base LLM. But the difference between o3/o4-mini and o1 seems like squeezing more juice out of the same lemon—from 70% to 90%, as it were—rather than starting on a whole new fruit.
The optimistic case would be “shut up and scale”: we can keep stacking OOMs, and research-level math is somewhere out there, up and to the right. But another researcher at OpenAI had this to say, trying to deflate some of the hype from someone claiming OpenAI had “solved math”:


“More research” doesn’t sound like scale. I read this as Brown saying that the next leg up on math performance is not obviously in sight.
Beyond math, I found it notable that OpenAI announced their Pioneers Program, which will focus on creating domain-specific evaluations and fine-tuning reasoning models in these domains. That makes sense to me in terms of evolving how we evaluate AI systems, as I’ve written. But it also may mean that OpenAI will be placing less relative emphasis on math capabilities going forward.
So, we may be in for a bit of a lull—though I say this half just to jinx Claude 4.0 into posting a surprising USAMO score or AlphaProof into getting a public release. Become complacent at your own risk!
OpenAI has previously reported higher scores on FrontierMath from internal evaluations: as high as 32% for o3-mini-high. I think the best explanation for these higher numbers is that OpenAI has better tools for eliciting performance from their models, maybe including having the models “think” for longer. I didn’t see any updated FrontierMath numbers with their latest release, but it seems reasonable to assume the elicitation gap is roughly the same from model to model, so maybe we shouldn’t expect a substantially different trend.
In previous posts I had been using ChatGPT for these experiments. However, the ChatGPT interface for o3 and o4-mini-high now has code and search tools automatically enabled. You can disable them, but the subsequent performance on math problems appears to be significantly degraded. Maybe the ChatGPT system prompt encourages the model to use these tools, so when they are disabled it is somehow confused about what to do; I don’t know. I’ve switched to using the API for now, which doesn’t seem to expect tools by default. I mention this just in case it helps anyone else in their own explorations.
I’m pretty sure that 2024 IMO P1 is within its reach, and we know it can sometimes get 2025 USAMO P5, since it did 1/4 times on MathArena. It just so happens that it got both wrong in this sample.